
Redis - so much more than I thought it was
“Redis is cool tech, the best option when you need a fast cache.”, that summarizes my image of Redis until sometime ago when I truly started to research modern data platforms in connection to application modernization efforts.
We found one of the most challenging problems in modernization was not so much the modernization of the codebase. Seperating and rewriting the high business value functionalities from a legacy monolithic core and coupling them through APIs is a well established practice, but how do you do the same with that huge underlying RDBMS database coupling everything together? Opening the database and trying to do something similar in this layer would most often be like opening Pandora’s box.
I discovered Redis did have good solutions for this problem, and I started to figure out how much it had evolved since I last used it as a developer myself.
A lot happened since, and I won’t bore you with the details. When I came into contact with Redis - the company - a year or so ago, I already knew it was cool tech and people love to use it, and it was more than ‘just a cache’. After joining Redis myself last March, I realized I still barely scratched the surface in my earlier research.
In this blog, I’ll share some of the stuff I would have liked to know when I was still in the field helping organisations with their app modernization and (real-time) data challenges.
Disclaimer: I work at Redis so yes I’m most definitely biased. Always do your own research.
For dev
1 - persistence
Redis is fast*. That’s because it’s an in-memory (RAM) database, and because it has been engineered from the ground up for performance. But what happens when the processes crashes and is restarted? Will the data be gone forever?
* Fast = <1ms latency with 25k ops/second on a single thread
Without the option to also persist data to durable storage, yes it would be. That’s why for something to be used as more than a cache, it requires persistence. There are different persistence modes in Redis, but suffice to say they are there and they work, allowing you to use Redis as a front-end database or even the primary database of the system. The astute reader may point out that for a reliable operational model you need more than just persistence. I will come back to those requirements below.
2 - all the data types you need in one place
Redis is a NoSQL database. This means you won’t get the old SQL transactions, tables, foreign and unique key-contraints, etc. I was ‘raised’ as a developer in a time where SQL was the only option, so we did everything with it. While it is convenient you don’t have to think about data consistency in your code, there are serious drawbacks as well, mostly in terms of speed, data size, and scalability. When I reflect on old projects, I wonder how often I really needed that absolute - stop the world - level of forced consistency in the database layer.
What you get back when you drop that constraint is raw speed and scalability. And Redis does this by offering a plentitude of datatypes that are more native to the developer than forcing everything in tables. For instance, in Redis you would use Strings for caching, Hashes for storing session state, Streams for event stream processing, Hyperloglog for counting unique events (visitors), Lists for queues, Geospatial indexes for location based services, Sets for recommendations, Sorted Sets for ranking/leaderboards, Time series for storing and working with time series data, Pub/Sub for messaging/notifications, and Vector for working with AI. If you need to store structured data beyond the capabilities of Hashes, Redis can work natively on JSON documents, without the need to serialize/deserialize in the application layer.
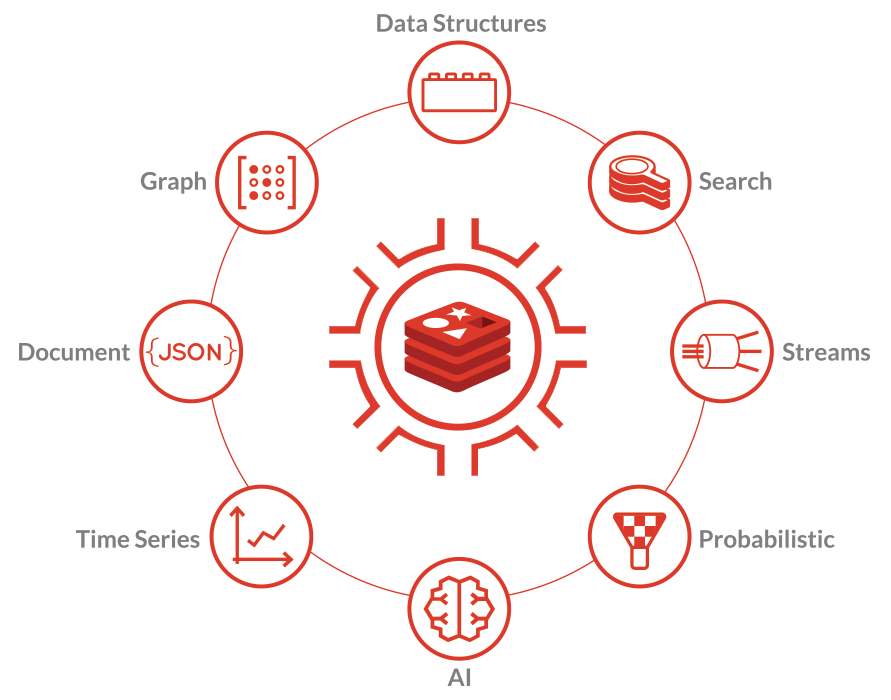 Some oft used Redis datatypes and example values
Some oft used Redis datatypes and example values
On all these types, you can do atomic operations.
Redis can fit relational models as well of course, but nobody will enforce the constraints (in fact you can’t even define them). You’ll also have to normalize the model which can be confusing at first for people - like me - who are hardwired to thinking in relational models.
In the end, there is not that much you can’t do with Redis. And this makes it convenient for you as a developer, and it also makes the typical application architecture much more simple.
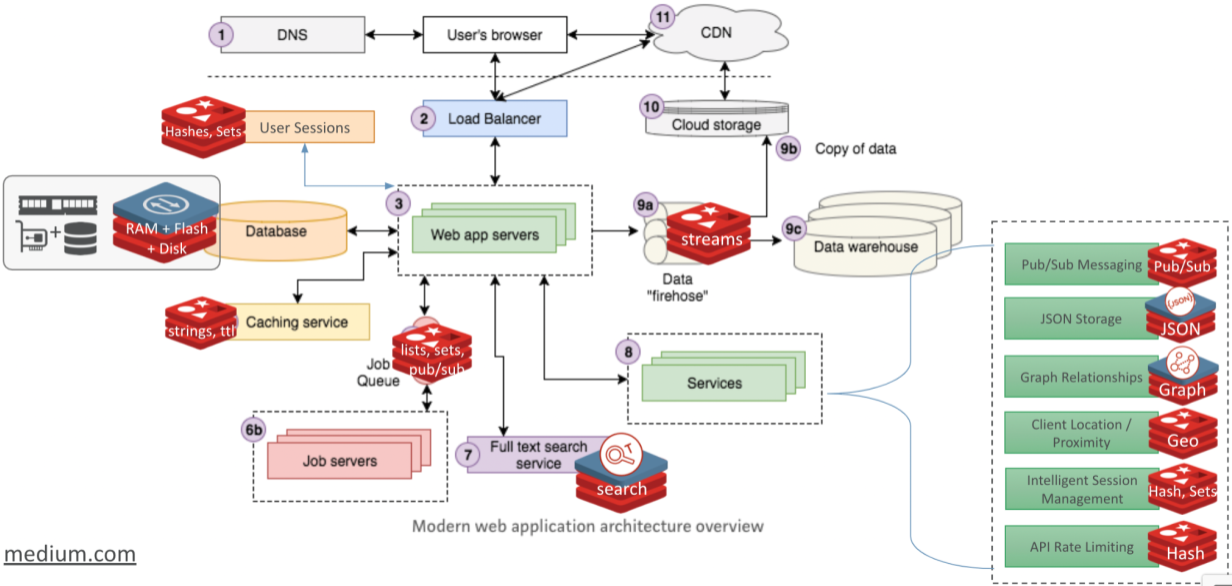 Modern microservices application architecture, and Redis functionality
Modern microservices application architecture, and Redis functionality
The days of a seperate tool for every use case are over.
3 - full text search
On top of all this Redis comes with full text search capabilities. Did I mention Redis is fast yet? I may have. So needless to say full-text search is fast as hell as well, enabling things like autocomplete, exact and fuzzy search, secondary indexing, and quick queries over huge datasets and JSON documents.
4 - rich ecosystem, quick to start
Redis is popular, and this has made it easy to get started, as it has led to the creation of 100s (no joke) client libraries for a huge number of languages and frameworks, so there is always a client for your language of choice. Depending on the client they are community or Redis maintained. Some of the community ones are of the highest quality: a good example is the C#/.NET community client maintained by StackExchange/StackOverflow.
If you (like me) appreciate declarative data (object mapping/index/search) and functional queries there are ‘Redis OM’ libraries for the most abundant frameworks (right now that means Node, .NET, Java/Spring and Python).
For development, it’s also easy to bootstrap a database with all the functionality above. Just launch the redis/redis-stack Docker image and open port 6379, connect your client library to localhost:6379 and you’re off to the races.
For ops
The operations story is more complicated, and possibly this is also the reason why I couldn’t see the forest for the trees before. The complication lies in the fact that open source Redis (Redis OSS) comes with certain features for availability, failover and scaling. It is ok, but has certain limits. Redis - the company - has created Redis Enterprise Software (RE), which uses the same open source database, but has a wildly different and frankly better operational architecture - which isn’t open source - pushing those limits even further.
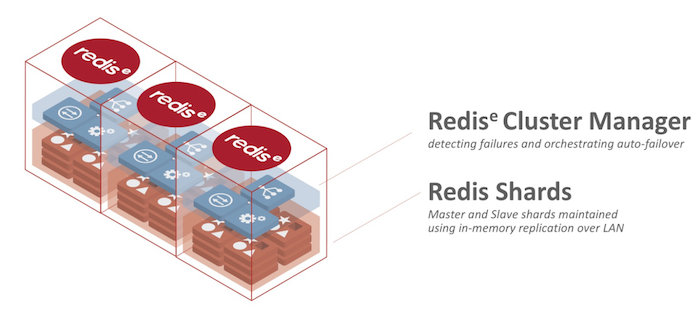
Redis Enterprise Software ‘cluster’ architecture with the Redis OSS databases ‘shards’, packed together with dedicated cluster management software inside a RE Software ’node’ (VM)
So a lot of the things below ‘depend’ on whether you use a version of Redis OSS (potentially wrapped by a cloud provider), or use RE (Software - or managed cloud as Redis Cloud).
Another complication comes from the usage of concepts like ‘shard’, ’node’, ‘cluster’ in the documentation of both Redis OSS and RE, but they technically mean different things. It’s very easy to get confused here.
1 - high availability
When we spoke about persistence, we said just having that is not enough for reliably offering a database service. Additional requirements are usually defined in terms of availability (%) and Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
You can get to 3 to 5 9’s of availability - so 99.9% up to 99.999% - depending on the way Redis is deployed.
For starters, Redis comes with a replication feature. When enabled, the ‘primary’ database will constantly synchronize data to a second database - the ‘replica’. This sets you up for quick failover in the case the master stops working.
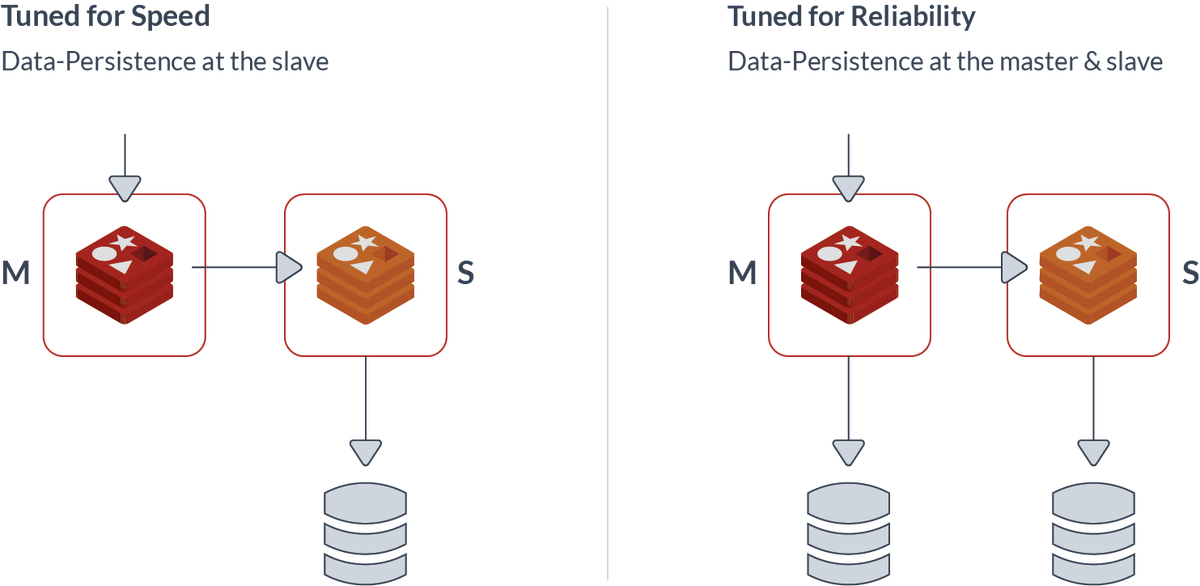 Redis primary and replica setup combined with storage. By default RE Software is tuned for speed
Redis primary and replica setup combined with storage. By default RE Software is tuned for speed
However, something needs to detect the failure and take action. This is where Redis OSS and Redis Enterprise Software/Cloud deviate. In Redis OSS, there are two ways in which you can do this (called ‘sentinel’ and ‘cluster’), but whatever you do, you will always need at least 3 ‘boxes’ (VMs, bare metal) for every highly available database to get quorum to take action on failures. And this will get you up to 99.9% availability (9 hours of downtime yearly).
With RE, the failover will be in seconds (better RTO) and the waste of infrastructure will be less, as you will always have at least 3 boxes total running the cluster control software and any number of databases. This pushes availability to 99.99% (1 hour of downtime/year).
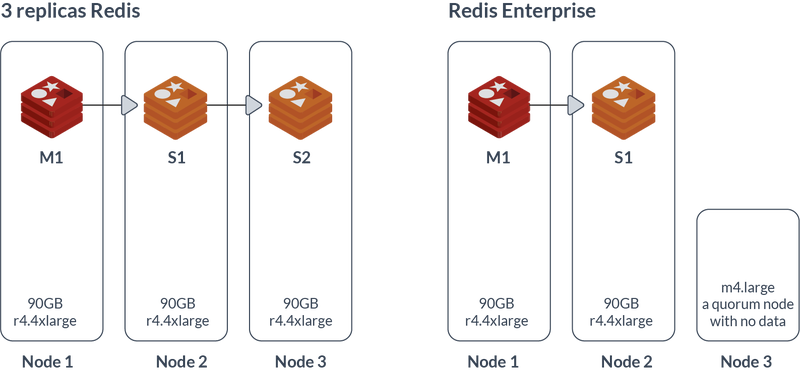 Example of the same database on Redis OSS cluster vs. RE Software cluster. The database on RE Software has faster failover and lower infrastructure demands as RE observes quorum on the cluster level (vs. database level in Redis OSS).
Example of the same database on Redis OSS cluster vs. RE Software cluster. The database on RE Software has faster failover and lower infrastructure demands as RE observes quorum on the cluster level (vs. database level in Redis OSS).
But RE Software can go even higher. The Redis active/active architecture can link multiple RE clusters - anywhere in the world! - to synchronize in real-time. Quite a feature on its own serving various use cases, it has the side-effect of pushing availability to 99.999% (5 minutes of downtime/year).
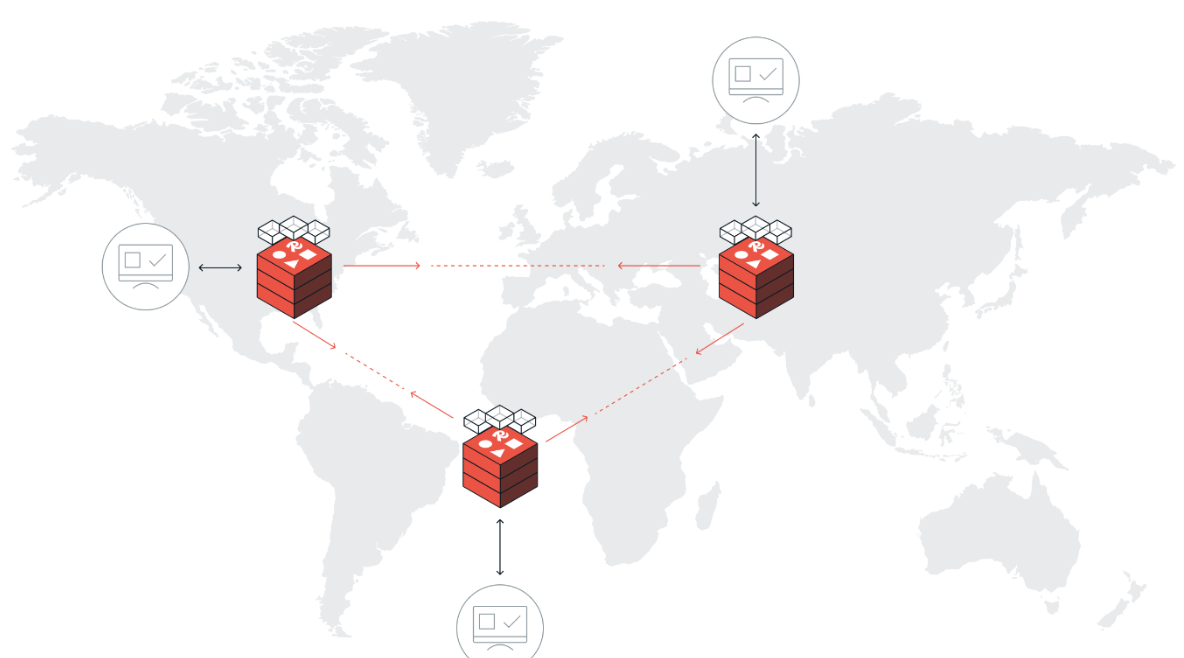
2 - geo-distribution
While active/active geo-distribution option allows you to reach up to 5 9’s of availability, there is much more to say here. For organisations that have users/customers around the world, this enables you to service them from the same database with the same sub millisecond latency Redis is known for thanks to so called conflict-free replicated data types (CRDTs).
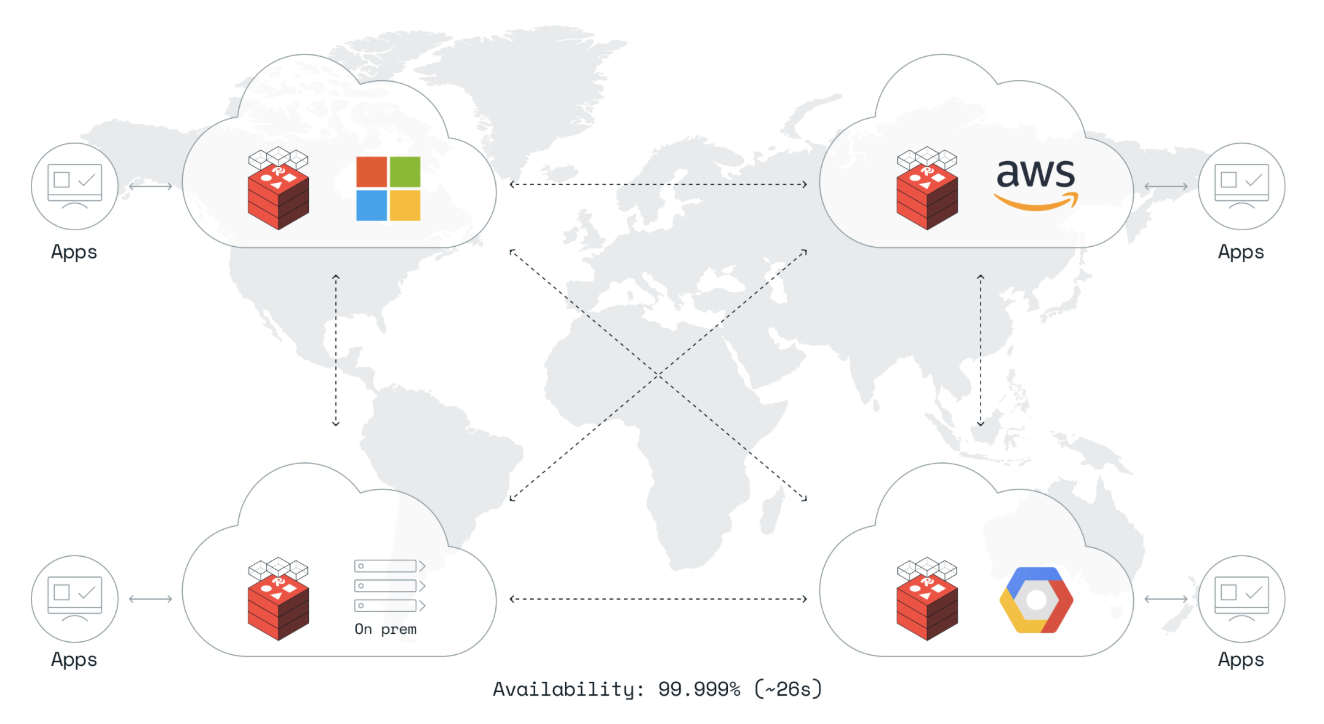
The RE clusters that are linked in this fashion can be on any cloud or in any datacenter in the world, enabling true multi/hybrid data applications.
3 - backup/restore & disaster recovery
Even with persistence, backups are required for data you don’t want to lose, since however unlikely, disks may still crash and (cloud) VMs may magically disappear. So taking the backup here means ‘saving the database to another failure domain’. Since persistence is included in Redis OSS, taking backups is as well. It may depend on the exact version of Redis OSS, cloud provider hosted OSS, or Redis Enterprise/Cloud how user friendly and automated this process is.
For disaster recovery the backup process above is used as well, but here you should interpret ‘failure domain’ as a reference to another datacenter.
Depending on the persistence mode that was used, it’s possible to get RPO up to seconds or even the instant before failure.
4 - linear scaling
Redis is by design a single-threaded database. This comes with many advantages, but it also means scaling out a Redis instance vertically beyond a few CPUs to get more performance is pointless (adding more RAM or frequency could be another story). To get more performance, Redis comes with a cluster feature, allowing it to scale horizontally, spreading the data across multiple instances.
RE Software features a real shared nothing cluster architecture, allowing for near linear scaling (tested up to 200M ops/sec). Redis OSS is more limited, the clustering mechanism causes overhead tapering the linear scaling. Depending on your dataset, this may or may not hurt you.
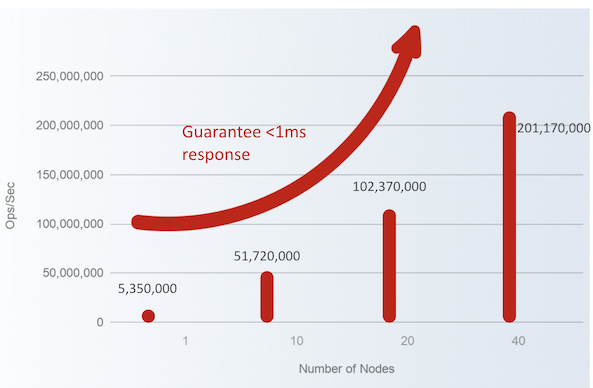
RE Software 94% linear scaling at 40 nodes and 200M ops/sec. At that speed, you can process all of 200B annual VISA transactions in just 1000 seconds.
5 - multi tenancy & automation
In Redis OSS, it is possible to define and apply ACLs on key/namespaces in the database and control access. RE Software takes this a step further and does the same at the logical cluster level, which allows for full multi-tenancy, but also for full automation of database creation within the cluster.
6 - efficient use of infrastructure
As said above with Redis OSS a highly available database always requires at least 3 boxes, where adding a new highly available database to a RE cluster doesn’t create new infrastructure. Depending on the number of databases, we have seen organizations reduce their cloud/infra spend so much by moving to RE Software they had a return on invest (RoI) of weeks/months.
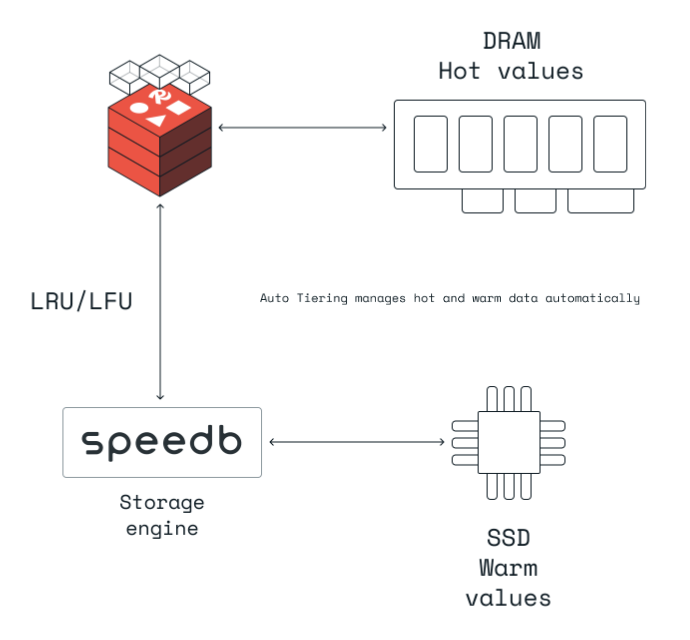
For very large datasets (>5TB), its possible to enable Redis to make use of 2nd level tiered memory in the form of (NVMe) SSDs. This feature called BigStore/Redis-on-Flash/Auto-tiering/Redis Flex can significantly reduce infrastructure cost and is only available in RE.
7 - deployment options
The easiest form of consumption will undoubtedly be the cloud model. There are multiple options here. forked versions of Redis OSS is available in a wrapped version on the hyperscalers: AWS Elasticache and GCP Memorystore. You can get Redis Enterprise directly from Redis, or through the cloud provider catalog (AWS, GCP), or even as a first party service (Azure Managed Redis).
Redis can also be deployed as software. Again on cloud infrastructure, or on-premises. You’ll have to compile, deploy and support it yourself, unless of course you take the RE version which even comes as a Kubernetes Operator.
When to choose which offering?
As I work for Redis the answer is: “always pick Redis Enterprise Software when you deploy it on your own infra, and pick Redis Cloud for managed offerings” :) All jokes aside, you may get a good run with Redis OSS. Redis is cool tech, and it’s fast.
The main reasons for chosing a Redis - the company - offered version over Redis OSS based ones are:
- reaching the limits of Redis OSS scaling/availability
- cost saving (better use of infrastructure)
- desire for having a supported offering, with improved installation/lifecycle management tooling
- setup real multi-tenancy with mature security features and controls
- active/active geo-distributed or hybrid/multi cloud use case
- features not in hosted Redis OSS versions (like JSON, Search, Timeseries, Vector, Geo redundancy)
So…what about app modernization?
You caught me. I highlighted all the good stuff but forgot to talk about the migration story. Truth be told, this post was already getting long and this topic deserves a seperate blog post. I set the stage and will spend time on this in a future post.
Note: updated in June 2025